실행 결과 해석: - 각 이름 뒤에 ’님’을 붙이고, 인사말을 결합했습니다. - str_c는 벡터화된 연산을 지원하므로, 각 요소별로 결합이 이루어집니다.
예제 2: 문자열 길이와 부분 추출 (str_length, str_sub)
# 데이터 프레임 생성df <-tibble( 제품명 =c("사과주스", "오렌지에이드", "딸기스무디", "바나나우유"), 가격 =c(3000, 3500, 4000, 2500))# 문자열 길이 확인df %>%mutate(글자수 =str_length(제품명))# 첫 두 글자만 추출df %>%mutate(축약명 =str_sub(제품명, 1, 2))
실행 결과 해석: - str_length()로 각 제품명의 글자 수를 계산했습니다. - str_sub()로 제품명에서 첫 두 글자만 추출하여 축약명을 만들었습니다.
예제 3: 패턴 매칭 (str_detect, str_count)
# 메뉴 데이터 생성menus <-c("아메리카노", "카페라떼", "카페모카", "녹차라떼", "초콜릿라떼")# '라떼'가 포함된 메뉴 찾기menus[str_detect(menus, "라떼")]# 각 메뉴에서 '카페' 단어 개수 세기str_count(menus, "카페")
실행 결과 해석: - str_detect()로 ’라떼’가 포함된 메뉴만 필터링했습니다. - str_count()로 각 메뉴에서 ’카페’라는 단어가 몇 번 나타나는지 계산했습니다.
예제 4: 문자열 대체 (str_replace, str_replace_all)
# 주소 데이터 생성addresses <-c("서울시 강남구 테헤란로","서울시 서초구 반포대로","서울시 종로구 종로")# '시'를 '특별시'로 변경str_replace(addresses, "시", "특별시")# 띄어쓰기를 '_'로 모두 변경str_replace_all(addresses, " ", "_")
실행 결과 해석: - str_replace()로 첫 번째 ’시’만 ’특별시’로 변경했습니다. - str_replace_all()로 모든 띄어쓰기를 밑줄로 변경했습니다.
예제 5: 고급 패턴 매칭 (정규표현식 활용)
# 이메일 데이터 생성emails <-c("user1@gmail.com","user.2@naver.com","user_3@company.co.kr","invalid.email","user4#company.com")# 이메일 형식 검증is_valid_email <-str_detect( emails,"^[[:alnum:]._%+-]+@[[:alnum:].-]+\\.[[:alpha:]]{2,}$")# 결과 확인tibble( 이메일 = emails, 유효성 = is_valid_email)# 도메인 추출domains <-str_extract(emails, "@[[:alnum:].-]+\\.[[:alpha:]]{2,}$")str_remove(domains, "@")
실행 결과 해석: - 정규표현식을 사용하여 이메일 주소의 유효성을 검사했습니다. - str_extract()로 이메일에서 도메인 부분을 추출했습니다. - str_remove()로 추출된 도메인에서 ‘@’ 기호를 제거했습니다.
6. 텍스트 빈도 분석과 시각화
텍스트 데이터를 분석하고 시각화하는 실전 예제를 살펴보겠습니다.
Code
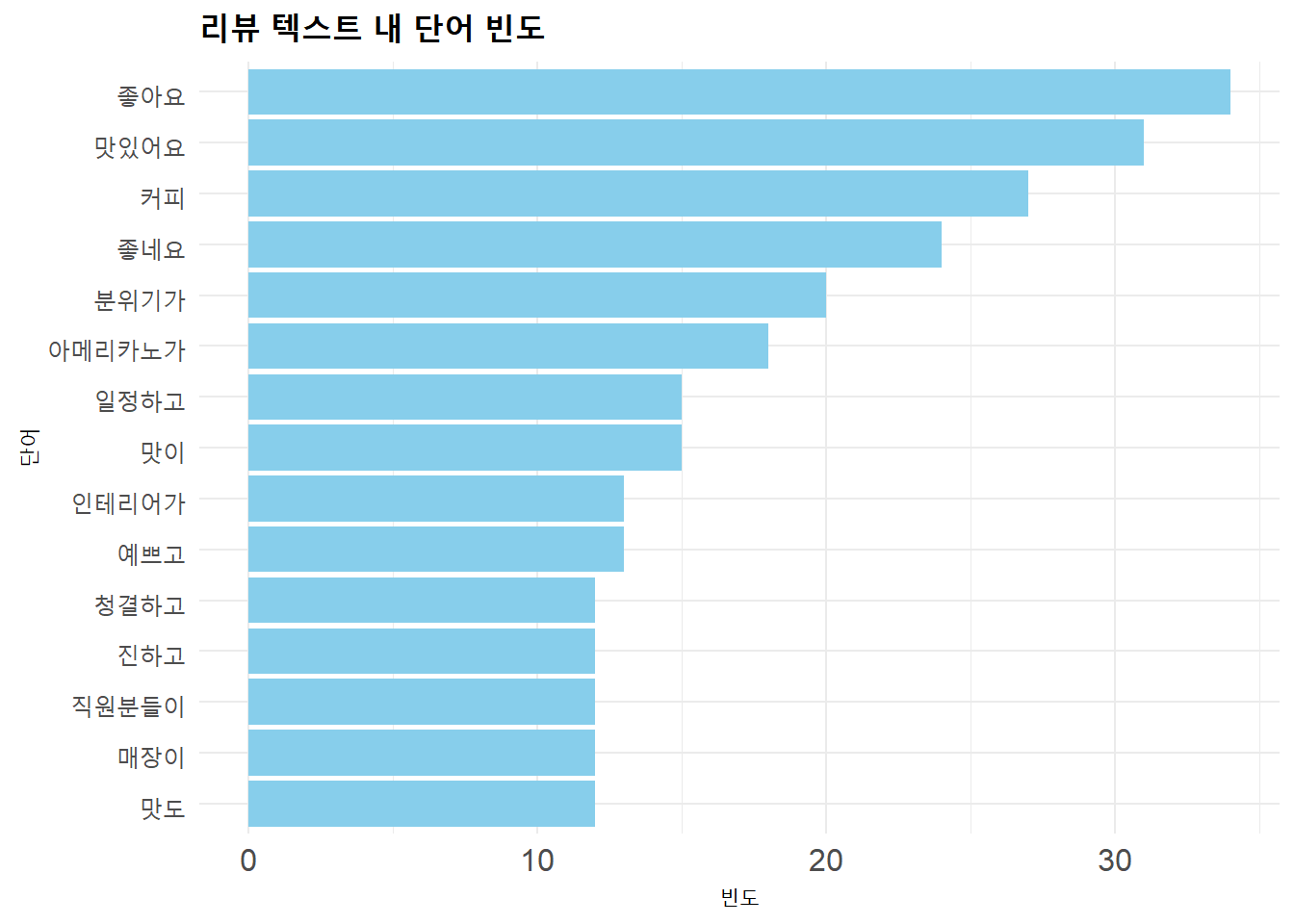
# 필요한 패키지 로드library(stringr)library(tidyverse)library(wordcloud2)library(tidytext)# 샘플 리뷰 데이터 생성set.seed(123)reviews <-tibble(id =1:100,review =c("커피가 너무 맛있어요. 특히 아메리카노가 좋아요","분위기가 좋고 커피도 맛있어요","직원분들이 친절하고 커피 맛도 좋네요","케이크가 맛있어요. 커피와 잘 어울려요","가격이 조금 비싸지만 맛있어서 자주 와요","인테리어가 예쁘고 분위기가 좋아요","아메리카노가 진하고 맛있어요","디저트가 맛있고 직원분들도 친절해요","커피 맛이 일정하고 좋아요","매장이 청결하고 좋네요" ) %>%sample(100, replace =TRUE) # 100개의 리뷰로 복제)# 단어 빈도 분석word_freq <- reviews %>%unnest_tokens(word, review) %>%# 텍스트를 단어로 분리count(word, sort =TRUE) %>%# 단어 빈도 계산filter(str_length(word) >1) # 한 글자 단어 제외# 상위 15개 단어 빈도 시각화word_freq %>%head(15) %>%ggplot(aes(x =reorder(word, n), y = n)) +geom_col(fill ="skyblue") +coord_flip() +labs(title ="리뷰 텍스트 내 단어 빈도",x ="단어",y ="빈도" ) +theme_minimal() +theme(plot.title =element_text(face ="bold", size =14),axis.text =element_text(size =12) )